Expand Briefing
This piece reflects a personal analytical framework based on public information and systems-level reasoning. It is not investment advice.
Overview
A common way to think about model progress is to treat it like traditional software iteration: adjust the architecture, tune parameters, release a better version, and capability improves. For frontier models, that view is now too narrow.
Frontier model performance is increasingly shaped not by algorithmic improvements alone, but by the interaction of algorithms, training scale, memory capacity and bandwidth, cluster communication, and inference-time compute. Algorithms still determine direction. But they no longer determine the ceiling in isolation.
Framework note: This essay treats frontier model progress as a systems problem, where capability gains increasingly depend on scaling compute, memory, communication, and inference infrastructure together.
1. Why the Old Mental Model Is No Longer Enough
Many market participants still interpret model improvement through the lens of traditional software progress. In that framing, better models emerge mainly from smarter architectures, better tuning, or more refined optimization. For frontier models, that mental model is incomplete.
For frontier models, performance gains are increasingly tied to whether larger training runs can actually be executed, whether memory systems can sustain the data flow, whether distributed clusters can coordinate efficiently, and whether inference itself can be scaled economically. As a result, the market's later shift toward compute, memory, interconnect, and data centers was not an arbitrary narrative extension. It was a direct response to the technical path itself.
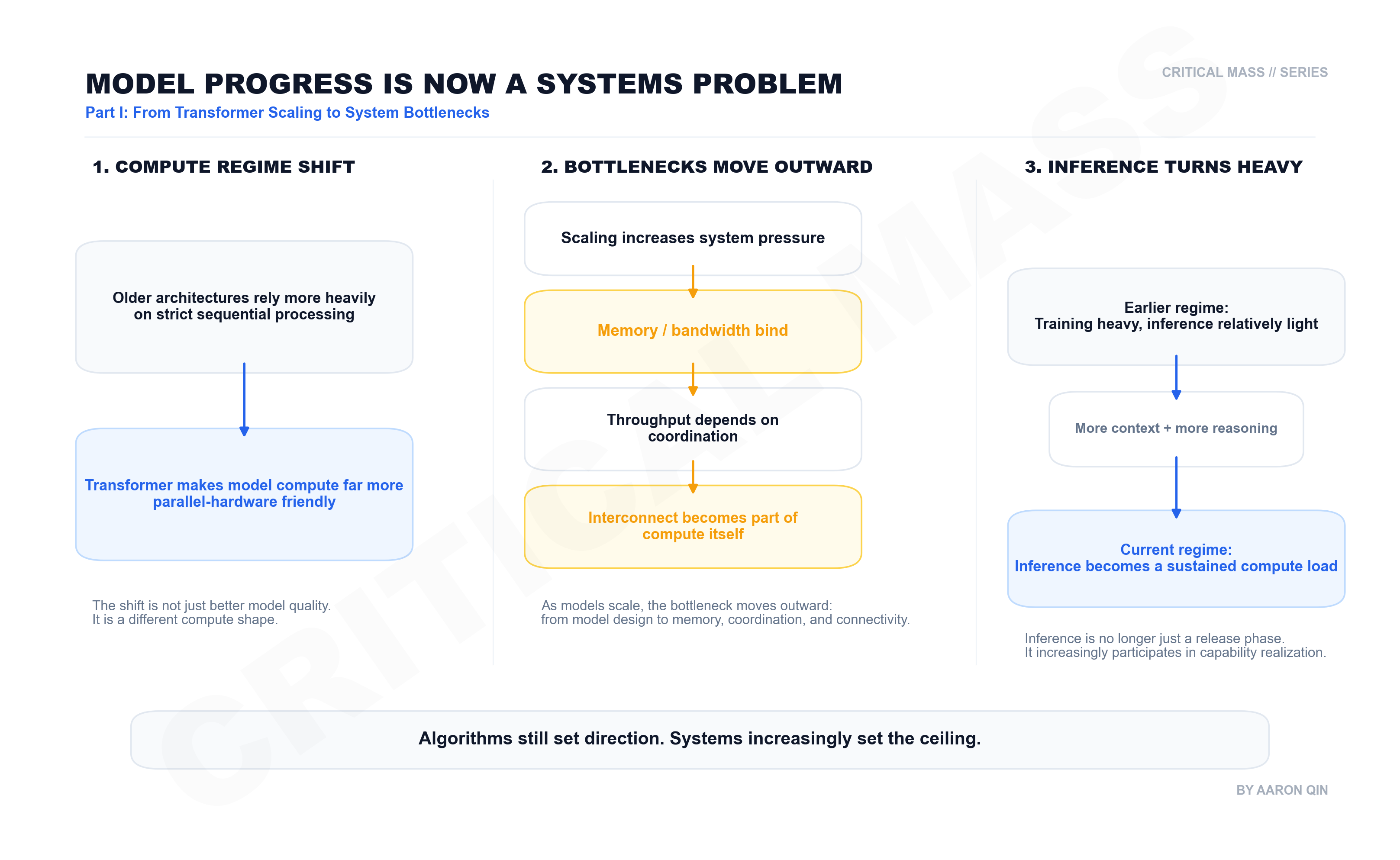
2. Transformer Changed the Shape of Computation
Most commercial frontier models still sit within the Transformer family.
That does not mean every system looks identical. Some models add mixture-of-experts (MoE) structures with sparse activation. Some extend into multimodal encoders. Others modify attention to support longer context windows. But these remain engineering variations built on top of the same broad computational regime.
Transformer improved model quality and changed the shape of computation.
Older neural architectures were far more dependent on strict sequential processing. Transformer shifted many of those operations into large-scale matrix computation, which maps far better onto parallel hardware such as GPUs and TPUs. Its significance is therefore not limited to model outcomes: it also pushed model progress onto a path that naturally depends on modern accelerators.
3. Scaling Turned Capability into a Systems Problem
Once model progress became tied to scaling, capability gains could no longer be explained by architecture alone.
This is where work such as Chinchilla matters. Its importance was not simply the claim that bigger models are better. The deeper point was that under a fixed compute budget, model size and data scale have to be matched efficiently. If parameter count rises without enough training data and effective compute, scaling becomes suboptimal.
The important takeaway is broader than any one recipe: frontier model improvement had already become deeply tied to training scale itself.
That means the question stops being only, “Can someone invent a better structure?” and becomes, “Can this system actually be run at the scale required to realize the capability?”
4. Distributed Training Pushed Bottlenecks Outward
As models continue to scale, the next bottlenecks are no longer conceptual. They are physical.
The first constraint is often memory capacity. Parameters take space. Activations take space. Intermediate training states take space. Eventually a single machine cannot hold the workload. Then training time becomes impractical, and the workload must be split across many GPUs.
Once training becomes distributed, the challenge changes. It is no longer only about whether the architecture is correct. It becomes a question of whether the full system can coordinate:
- how cross-node communication is handled,
- how pipeline stages are scheduled,
- how different forms of parallelism are combined.
At this point, frontier models are not something you can “just write down.” They have to run reliably across large distributed clusters. That is the moment when system scalability begins to constrain the ceiling of model capability.
5. Memory Movement Matters as Much as Arithmetic
As soon as workloads are spread across many machines, the system stops consuming only raw compute. It also consumes memory capacity, memory bandwidth, and communication efficiency.
Optimizations such as FlashAttention matter because they expose where the bottlenecks are moving.
FlashAttention is not a new model paradigm. It is an implementation-level optimization around attention. Its significance lies in what it reveals: for large models and long contexts, the bottleneck is often arithmetic and data movement together.
Moving data between high-bandwidth memory and on-chip storage is itself a cost. In other words, many of the bottlenecks in frontier systems come not from “too much math,” but from “too much movement.”
Algorithmic progress increasingly looks like an effort to improve resource utilization rather than an escape from resource dependence.
6. Inference Is Becoming Compute-Heavy Too
Another major change is that inference itself is no longer a light phase.
It used to be easier to think of inference as simple deployment: train the model once, then let it generate answers. That description is no longer sufficient. Longer contexts, more complex reasoning, and higher thinking budgets are turning inference into a sustained consumer of compute resources.
This means the cost structure of frontier models is changing on both sides:
- training is heavier,
- and inference is heavier too.
Capability is no longer formed entirely during training and merely released during inference. Inference is increasingly participating in capability realization itself. That further reinforces the core point: frontier model competition is no longer only a competition among training algorithms. It is a systems competition in which both training and inference are becoming more compute-intensive.
7. Synthesis
Algorithms still matter, but their place in the stack has changed.
Most commercial frontier models still belong, at their core, to the Transformer family. The significance of that family is not only better model quality; it is also the path it created toward large-scale computing systems as a condition for turning capability into reality.
From larger training runs, to higher demands on memory and bandwidth, to distributed communication, networking, and heavier inference budgets, capability improvement increasingly looks like a systems engineering problem.
The real shift is not that model progress moved from being an algorithm problem to becoming a hardware problem. It moved from isolated algorithmic optimization to a regime in which the upper bound is jointly determined by algorithms and systems.
Algorithms set direction, while systems increasingly shape the ceiling.
Sources and notes
This framework note is anchored in broadly recognized technical and industry developments rather than a single company event:
- Transformer Compute Regime: The continued dominance of Transformer-family architectures across frontier commercial models.
- Scaling Logic: Chinchilla-style scaling work highlighting the relationship between compute budget, parameter count, and data efficiency.
- Distributed Training Constraints: The role of memory capacity, bandwidth, and cluster communication in large-scale training.
- Attention Optimization: FlashAttention as evidence that data movement, not just arithmetic, has become a first-order systems bottleneck.
- Inference Load Expansion: The growing importance of longer context windows, reasoning workloads, and inference-time compute budgets.