Expand Briefing
Executive Summary
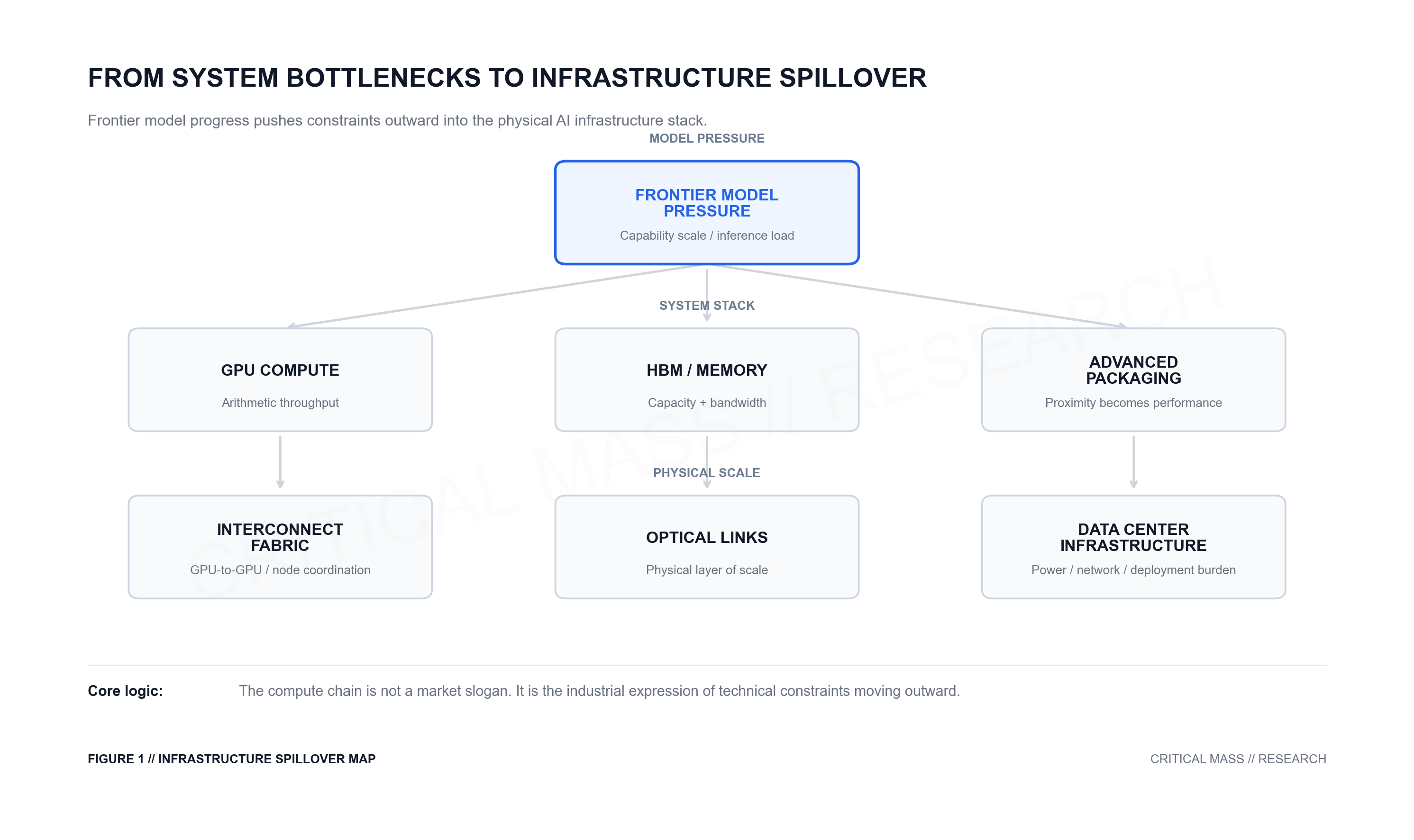
Part I argued that frontier model progress is no longer governed by algorithms alone. As model capability becomes more dependent on training scale, memory systems, distributed communication, and inference-time compute, the bottleneck moves from model design into the broader computing system.
Part II asks what follows from that conclusion.
If model progress is increasingly constrained by systems, then those constraints will not remain inside the model. They will propagate outward into the infrastructure stack: GPUs, high-bandwidth memory, advanced packaging, switching fabrics, optical interconnects, and data center networks.
This is the real logic behind what the market often calls the “compute chain.” It is not a supply-chain story invented by investors after the fact. It is the industrial expression of technical bottlenecks moving outward.
Core Argument: The AI infrastructure stack is not a collection of fashionable concepts. It is the physical and industrial response to one system-level question: how can frontier model capability be delivered at larger scale, higher stability, and lower friction?
1. Why System Constraints Matter for Markets
After Part I, the natural question is: why spend so much time discussing system constraints?
If the discussion remains too abstract, it can easily become a kind of technology commentary that sounds sophisticated but does not improve judgment. The real value is not in sounding more technical. The value is in changing how we read the market.
For investors focused on deep technology, the point is not to memorize more terms. It is to distinguish between surface narratives and hard constraints.
The better question is not: which story is the market talking about now?
The better question is: where is the system actually constrained?
That shift matters. It changes the focus from chasing the newest concept to identifying the layer of the stack that is closest to the bottleneck.
2. Compute Is Not Just Compute
The first term that needs to be unpacked is “compute.”
In market language, compute is often treated as if it simply means faster chips. But for frontier models, that view is too narrow.
The relevant system is not just arithmetic throughput. It includes whether the model can fit in memory, whether data can be fed into the accelerator fast enough, and whether machines can communicate efficiently with one another.
In practical terms, compute is a bundle of three things:
- calculation
- memory
- connectivity
A system can have strong peak compute on paper and still fail to deliver effective throughput if memory, bandwidth, or communication becomes the bottleneck.
That is why leading AI systems are not described only through peak FLOPS. They are increasingly discussed through the combined architecture of accelerators, memory capacity, memory bandwidth, and interconnect.
The important unit is no longer a single chip metric. It is whether the whole system works together.
3. Memory and Bandwidth Become First-Order Constraints
Once compute is unpacked, the first major constraint that emerges is often not the compute unit itself. It is memory capacity and bandwidth.
As models become larger, the problem is not simply that there is more to calculate. The problem is that there is more to store, move, and feed.
Parameters take space. Intermediate states take space. Longer context windows increase cache pressure and data movement. Eventually the question shifts from “Is the chip fast enough?” to “Can the system hold and move enough data fast enough?”
This is why market attention has expanded from GPUs to HBM, or high-bandwidth memory.
HBM does not make a model more intelligent by itself. Its function is more basic and more important: it helps the system keep up as models become larger and more data-hungry.
In many cases, the first bottleneck to be re-priced by the market is not raw compute. It is the system’s ability to supply data to compute.
4. Packaging Turns Proximity into Performance
The memory problem then pushes outward into advanced packaging.
If a system needs larger compute dies, higher-bandwidth memory, and faster movement between them, then the physical arrangement of those components becomes a performance variable.
At that point, packaging is no longer just a manufacturing back-end detail. It directly affects whether the whole system can run efficiently.
This is why advanced packaging technologies such as matter. The point is not simply to put more components together. The point is to place accelerators and high-bandwidth memory close enough, densely enough, and efficiently enough to reduce data movement friction.
This is also why the market links GPUs, HBM, and advanced packaging together. They are not separate buzzwords. They are different layers responding to the same system problem:
how to move data faster through the compute stack.
5. Interconnect Becomes Part of Compute
Once the system cannot be contained within a single device, the next constraint is communication.
In a multi-GPU system, GPUs need to exchange data. In a multi-server system, machines need to synchronize. As clusters scale further, the switching layer and broader network topology become part of the constraint set.
At this stage, interconnect is no longer a peripheral accessory. It becomes part of the compute system itself.
This is the logic behind technologies such as and . Their role is not just to connect devices in a generic sense. They form a high-bandwidth GPU-to-GPU communication fabric for AI training, inference, and rack-scale workloads.
The progression is natural:
single GPU limits
→ multi-GPU parallelism
→ multi-node coordination
→ switching fabric and interconnect dependency
→ multi-GPU parallelism
→ multi-node coordination
→ switching fabric and interconnect dependency
This is not a story that markets invented. It is what happens when the system becomes too large for any single device to carry.
6. Optical Links Are the Physical Layer of Scale
As the network problem keeps expanding, it eventually reaches the physical layer.
When communication moves from inside a node to inside a rack, and then across racks, the question is no longer just whether the network architecture is elegant. The question becomes: what physical medium can actually carry high-bandwidth communication at scale?
This is where and optical interconnect begin to matter.
The logic is simple. Large-scale AI clusters need high-bandwidth links. Those links eventually have to become cables, ports, switches, transceivers, and optical paths.
In other words, optical components are not a concept artificially attached to the AI story. They are the physical expression of network scale.
You can describe interconnect in abstract terms, but at some point it has to exist in the real world. Once the cluster grows large enough, the physical network layer becomes impossible to ignore.
7. Inference Makes Infrastructure Demand Persistent
So far, most of the spillover has been driven by training-side pressure. But inference changes the duration of that pressure.
In the past, inference was easier to treat as a relatively light stage: train the model, deploy it, and generate answers.
That is no longer the right mental model.
Longer context windows, more complex reasoning, and higher thinking budgets are turning inference into a sustained compute workload. In many frontier systems, stronger answers are not only the result of what the model learned during training. They are also the result of allowing the model to spend more compute at inference time.
The trade-off is direct: better reasoning usually means more latency, more tokens, and higher cost.
This means the infrastructure stack is not only serving a one-time training boom. It is increasingly supporting a persistent deployment burden.
Training expands the problem.
Inference keeps the problem alive.
Inference keeps the problem alive.
For deep technology investors, this distinction matters. Some infrastructure demand may be cyclical or front-loaded. But if inference itself becomes heavier, then parts of the infrastructure stack may remain under long-term pressure during deployment and delivery, not just during the training race.
8. From Technical Bottlenecks to Market Language
The so-called compute chain is not a chain that markets created first.
It is what happens when technical bottlenecks propagate outward and are absorbed by industrial supply chains.
Each layer of model scaling raises a new constraint:
- compute
- memory and bandwidth
- packaging
- interconnect
- networking
- inference deployment
From the outside, the market may look like it is rotating from one theme to another. GPUs one day, HBM the next, then packaging, then optical transceivers, then power and data centers.
But from the system level, these themes are not random. They are different expressions of the same problem:
how to turn frontier model capability into larger-scale, more stable, and more continuous infrastructure reality.
That is the real value of understanding this chain. It is not about collecting more technical terms. It is about building a better filter.
Do not start with the hottest concept.
Start with the hardest constraint.
Do not ask who is telling the most exciting story.
Ask who is closest to the bottleneck the system cannot avoid.
Markets often chase novelty. But the more durable opportunities tend to cluster around constraints that become structurally unavoidable.
9. Series Conclusion
The point is not that the AI infrastructure stack is long. Nor is the point that every layer of the supply chain is equally attractive.
The point is that frontier model progress is being translated into a full infrastructure stack because the underlying technical constraints are spreading outward.
GPUs, HBM, advanced packaging, switching fabrics, optical transceivers, and data center networks are not just a list of hot themes. They are different layers of the same system-level problem.
Part I explained why model progress is no longer just an algorithm problem.
Part II explains why that system problem becomes an infrastructure stack.
The next question is different: once these constraints become visible, how does the capital market identify the true bottleneck, separate durable pressure from temporary theme rotation, and translate that into valuation, expectations, and trading language?
That is where the technical chain becomes a market framework.
The Research Trail
This series essay is anchored in broadly recognized technical and industry developments rather than a single company event:
- AI Infrastructure Stack: The market’s “compute chain” is better understood as a layered infrastructure stack spanning accelerators, memory, packaging, interconnect, networking, and deployment.
- Memory and Bandwidth Constraints: HBM and accelerator memory bandwidth matter because larger models increase pressure on storage, movement, and data supply.
- Advanced Packaging: CoWoS-style packaging matters because proximity between accelerators and high-bandwidth memory becomes a performance variable.
- Interconnect and Switching: NVLink, NVSwitch, and switching fabrics show how communication becomes part of the compute system itself at scale.
- Optical Networking: Optical transceivers and high-bandwidth links become relevant as cluster communication expands across racks and data center networks.
- Inference Load Expansion: Longer contexts, reasoning-heavy workloads, and higher thinking budgets turn inference into a persistent infrastructure demand rather than a light deployment phase.