Expand Briefing
Executive Summary
Part I argued that frontier model progress is no longer governed by algorithms alone. Model capability is increasingly shaped by the interaction of algorithms, training scale, memory systems, distributed communication, and inference-time compute. Part II extended that logic outward: once model progress becomes a systems problem, the bottlenecks do not stay inside the model. They propagate into the infrastructure stack: GPUs, high-bandwidth memory, advanced packaging, switching fabrics, optical links, and data center networks.
Part III asks what happens after the market sees that chain.
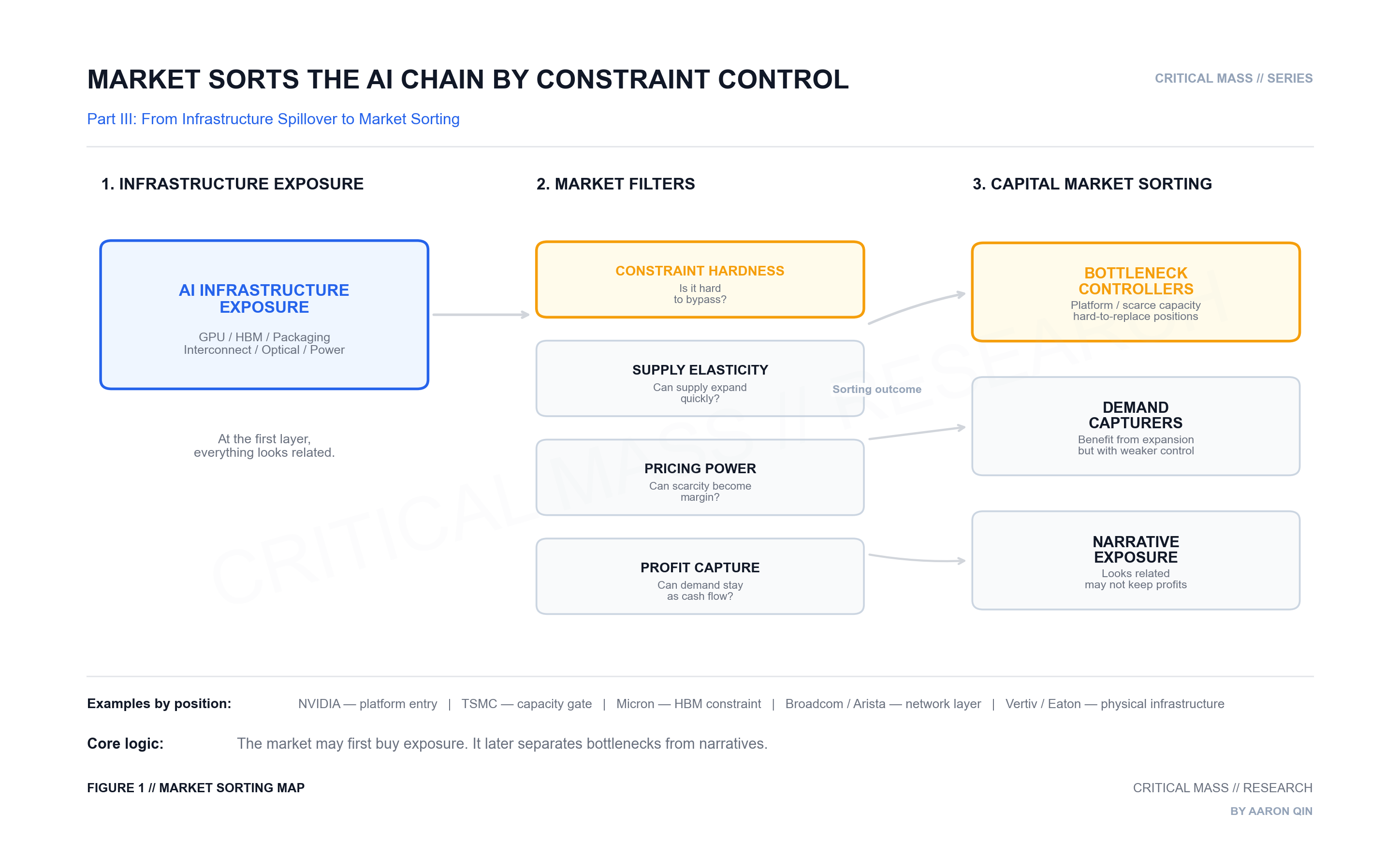
The key question is no longer only which companies are “AI beneficiaries.” That language is too broad. Many companies can benefit from AI infrastructure growth, but they do not benefit in the same way. Some control system entry points. Some control scarce supply. Some capture demand but have weaker pricing power. Others only sit near the narrative.
The market may first buy the whole chain. Over time, it separates bottlenecks from exposure.
Core Argument: The capital market is not simply trading stronger models. It is trading the constraints that stronger models make harder to bypass.
1. “AI Beneficiary” Is Not a Conclusion
The easiest phrase to use in this market is “AI beneficiary.”
It is also one of the least useful.
A GPU company can benefit from AI. A high-bandwidth memory supplier can benefit from AI. An advanced packaging provider can benefit from AI. A networking company, optical component supplier, data center operator, power equipment provider, or cooling infrastructure company can also benefit from AI.
But those are not the same kind of benefit.
The real question is not whether a company is connected to AI. The real question is how it is connected.
Does it control a system bottleneck?
Is its supply difficult to expand?
Can scarcity become pricing power?
Can demand turn into revenue, margin, and cash flow?
Is the customer forced to buy, or merely encouraged to buy?
Is its supply difficult to expand?
Can scarcity become pricing power?
Can demand turn into revenue, margin, and cash flow?
Is the customer forced to buy, or merely encouraged to buy?
Those questions matter because markets do not treat all beneficiaries equally for very long. In the early phase of a theme, almost everything connected to the main narrative can be bought together. But once expectations deepen, the market starts to sort.
Some companies control bottlenecks.
Some companies capture demand.
Some companies only carry exposure.
Some companies capture demand.
Some companies only carry exposure.
That distinction is where the investment framework begins.
2. System Entry Points Are Different From Ordinary Demand
The GPU and AI accelerator layer is not only about selling more chips.
At the frontier, the accelerator becomes the entry point into the system. Customers are not just buying arithmetic throughput. They are buying a working compute platform: hardware, networking, software libraries, developer tooling, deployment patterns, and migration costs bundled together.
That is why NVIDIA is not treated by the market like a generic semiconductor vendor.
NVIDIA’s fiscal 2026 revenue reached $215.9 billion, with fourth-quarter Data Center revenue of $62.3 billion. The point is not only that the numbers are large. The point is what they represent: the market is pricing NVIDIA as a system-level platform inside AI infrastructure, not merely as a component supplier. Its position combines compute, networking, software stack, and customer lock-in into one control point.
That is a very specific kind of AI exposure.
It is not the same as “demand is rising.”
It is closer to: the system has a dominant entry point, and one company controls much of it.
It is closer to: the system has a dominant entry point, and one company controls much of it.
This is why the market tends to assign a different quality to platform-like positions. They are not just exposed to demand. They shape how demand is served.
3. HBM Is a Bottleneck, Not a Platform
High-bandwidth memory is a different case.
HBM does not control the AI platform in the way an accelerator ecosystem can. It does not own the same software layer or customer workflow. But it sits close to one of the hardest physical constraints in the system: feeding data fast enough into increasingly large and bandwidth-hungry models.
That makes HBM a bottleneck asset, not a platform asset.
The market is not interested in HBM because “memory also benefits from AI.” That would be too shallow. The real question is whether memory bandwidth becomes a persistent constraint in training and inference systems.
Micron’s disclosure that its entire calendar 2026 HBM supply had completed price and volume agreements is important for this reason. It signals that high-bandwidth memory is not being treated like an ordinary memory cycle. It is being locked ahead of time because customers expect the constraint to matter.
This is a different investment logic from the GPU layer.
For HBM, the question is not: does the company control the AI platform?
The question is: is this part of the system scarce enough, and hard enough to expand, that demand can turn into better pricing, better mix, and more visible revenue?
That is why two companies can both “benefit from AI” while being valued for completely different reasons.
4. Packaging Is Where Capacity Becomes a Gate
Advanced packaging is another layer with a different logic.
It is not the most visible part of the system. Most users never think about it. But if the compute die and HBM cannot be placed close enough, densely enough, and efficiently enough, the system cannot fully realize the performance promised by the accelerator and memory stack.
At that point, packaging stops being a back-end manufacturing detail. It becomes a system-level capacity gate.
TSMC’s CoWoS capacity is a clear example. In its Q1 2025 earnings call, TSMC said it was working to double CoWoS capacity in 2025 to support customer demand. That matters because CoWoS is not just an auxiliary process. It is one of the ways advanced accelerators and HBM are integrated into deployable AI hardware.
The market is therefore not only pricing “advanced packaging as a theme.” It is pricing whether the system can actually be delivered.
This distinction matters. A component can be technically important but commercially weak if supply is easy to expand or pricing power is limited. But when a manufacturing layer becomes a gating factor for system delivery, the market starts to treat it differently.
Packaging in that case becomes less like a background process and more like a checkpoint in the AI infrastructure build-out.
5. Networking Is Where Cluster Scale Starts to Matter
Networking and interconnect are often misunderstood because they sound less central than the accelerator itself.
But once the model system becomes too large for a single device, communication becomes part of compute.
Multi-GPU systems require device-to-device coordination. Multi-server systems require synchronization across nodes. Larger clusters require switching fabrics, network interfaces, physical layer devices, and optical links. At that scale, networking is no longer just a background utility. It affects throughput, utilization, latency, and ultimately the economics of the cluster.
Broadcom’s description of its AI semiconductor solutions is useful here. It groups together custom accelerators or XPUs, Ethernet switching and routing silicon, Ethernet NICs, PHYs, optical components, and XPU-based racks and systems. That is not a single-chip story. It is an AI infrastructure supply story.
This is why the market has expanded from accelerators into networking names.
But again, not every networking exposure is the same. Some positions are closer to hyperscale architecture decisions. Some are more exposed to optical demand. Some are more replaceable. Some capture more value, while others mainly capture volume.
The right question is not whether networking benefits from AI.
The better question is: which part of the networking stack becomes harder to bypass as clusters scale?
6. Why Markets First Buy the Chain, Then Separate the Chain
This is the usual pattern.
At first, the market identifies the main direction. Frontier models need more compute. AI infrastructure spending rises. The most obvious winners get priced first.
Then the system keeps expanding.
Memory becomes tight. Packaging becomes a capacity gate. Networking becomes part of compute. Optical links become a physical layer of scale. Power and cooling become data center constraints. As each bottleneck becomes more visible, capital searches for the next layer of exposure.
From the outside, this can look like theme rotation.
One month it is GPUs.
Then HBM.
Then CoWoS.
Then optical networking.
Then power and cooling.
Then HBM.
Then CoWoS.
Then optical networking.
Then power and cooling.
But from the system perspective, it is not random. It is the market learning the shape of the constraint stack layer by layer.
Still, diffusion is not the same as durability.
Some exposures are real bottlenecks. Others are only demand transmission. Some companies can turn scarcity into margin. Others only receive orders during the expansion phase. Some positions are difficult to replace. Others can be competed away as supply expands.
That is why the market can temporarily place many companies under the same AI infrastructure narrative, but it will not permanently assign them the same quality.
The first phase buys relevance.
The later phase sorts control.
The later phase sorts control.
7. A More Useful Set of Questions
For deep technology investing, the question should not start with:
Is this company related to AI?
That question is too weak.
A better framework asks:
- What constraint does this company solve?
- Is that constraint becoming harder or easier?
- Can customers bypass it?
- Can supply expand quickly?
- Does the company have pricing power?
- Does demand convert into revenue, gross margin, and cash flow?
- Is this a structural pressure or a temporary cycle?
- Is the company controlling the bottleneck, or only sitting near it?
This is the difference between exposure and control.
A company can be exposed to AI demand and still fail to capture much value. Another company can sit at a narrower point in the stack but capture a disproportionate share of economics because customers have fewer alternatives.
That is why the phrase “AI beneficiary” should be treated as the beginning of analysis, not the end.
8. Mapping the Positions
If this framework is applied to actual companies, the point is not to build a simple “AI stock list.” The point is to understand what layer of constraint each company represents.
NVIDIA sits closest to the system entry point. Its strength is not only the GPU. It is the combined position across accelerators, networking, software stack, developer ecosystem, and customer switching costs.
Broadcom represents a different position: custom AI silicon and network infrastructure for hyperscale systems. Its AI semiconductor solutions span custom accelerators, switching, routing, NICs, PHYs, optical components, and rack-level systems. That makes it less of a pure accelerator story and more of an AI infrastructure supply-chain story.
TSMC represents advanced process and packaging capacity. In the AI accelerator stack, advanced packaging such as CoWoS is not just a back-end detail. It is part of whether the system can be produced and delivered at scale.
Micron represents the HBM constraint. It does not own the AI platform, but if high-bandwidth memory remains tight, the company’s position can be re-understood through the lens of bandwidth scarcity rather than only the traditional memory cycle.
Arista is closer to the AI networking layer. As clusters scale, network performance becomes more central to system throughput. This gives high-performance switching and cloud networking companies a different kind of exposure from accelerator or memory suppliers.
Credo represents a higher-beta connectivity position. It is closer to the high-speed connection layer. That can create strong upside when the network build-out accelerates, but it should not be valued with the same logic as a platform controller or a manufacturing capacity gate.
Eaton and Vertiv sit further down the physical infrastructure stack. They are not central to model capability formation in the same way accelerators or HBM are. But as AI data centers expand, power distribution, cooling, and deployment infrastructure become part of the physical burden of scaling.
All of these companies can be described as AI beneficiaries.
But they benefit in different ways.
Some control system entry points.
Some control scarce supply.
Some capture network expansion.
Some absorb downstream infrastructure burden.
Some have stronger pricing power.
Some are more exposed to cycle and competition.
Some control scarce supply.
Some capture network expansion.
Some absorb downstream infrastructure burden.
Some have stronger pricing power.
Some are more exposed to cycle and competition.
The difference matters.
9. Framework Conclusion
The point of this series is not to say that every company in the AI infrastructure chain is equally attractive.
It is almost the opposite.
Part I showed why frontier model progress has become a systems problem.
Part II showed why that systems problem spills outward into infrastructure.
Part III brings that logic into market language: once the chain is visible, the market begins to sort.
Part II showed why that systems problem spills outward into infrastructure.
Part III brings that logic into market language: once the chain is visible, the market begins to sort.
It asks which constraints matter most.
It asks which companies sit closest to those constraints.
It asks which positions can defend pricing power.
It asks which exposures can become cash flow, and which ones only remain narrative.
It asks which companies sit closest to those constraints.
It asks which positions can defend pricing power.
It asks which exposures can become cash flow, and which ones only remain narrative.
The market may first buy the whole chain. But over time, it separates bottlenecks from exposure.
That is the core lesson.
When looking at deep technology equities, it is not enough to ask who stands near the future.
The better question is:
who stands on the constraint?
Because in many technology cycles, the future does not distribute profits evenly. The durable economics often accrue to the places that the future has to pass through.
The Research Trail
This framework note is anchored in public company disclosures and the system-level logic developed in the previous two parts:
- NVIDIA: Fiscal 2026 revenue and Data Center results illustrate the scale and quality of platform-level AI infrastructure demand.
- Micron: 2026 HBM supply agreements show how high-bandwidth memory is being treated as a constrained supply layer rather than a generic memory category.
- TSMC: CoWoS capacity expansion highlights how advanced packaging can become a delivery bottleneck for AI accelerators.
- Broadcom: AI semiconductor disclosures show how custom accelerators, Ethernet switching, NICs, PHYs, optical components, and rack systems form a broader infrastructure supply logic.
- Critical Mass Part I and Part II: The earlier framework established why model progress became a systems problem and why system bottlenecks spill outward into infrastructure.
Disclaimer
This report is for informational purposes only and does not constitute financial advice. The methodology relies on engineering and market-structure reasoning, but market risks remain.