Expand Briefing
AI Systems | Digital Infrastructure | AI Infrastructure | Semiconductors
2026-06-11 · Framework Essay
2026-06-11 · Framework Essay
On January 27, 2025, NVIDIA lost roughly $600 billion in market capitalization in a single session. The trigger was the market's reaction to DeepSeek's reported training cost: roughly $5.6 million for DeepSeek-V3's final training run, a figure widely read as evidence that capable models might be built with far less compute than U.S. frontier-lab spending implied. The market drew an immediate conclusion: if capable models can be built cheaply, the infrastructure buildout must be overextended.
By early 2026, NVIDIA reported fiscal 2026 revenue of $215.9 billion, up 65% from the prior year. Hyperscaler capital spending had continued to accelerate. The market value lost in January had been recovered and exceeded.
What happened was not that the market was obviously wrong in January and obviously right by early 2026. What happened is that the original question — does efficiency hurt infrastructure demand? — turned out to be the wrong question. The right question is: not whether AI needs more or less compute, but what kind of compute, deployed where, under what latency, memory, utilization, and power constraints.
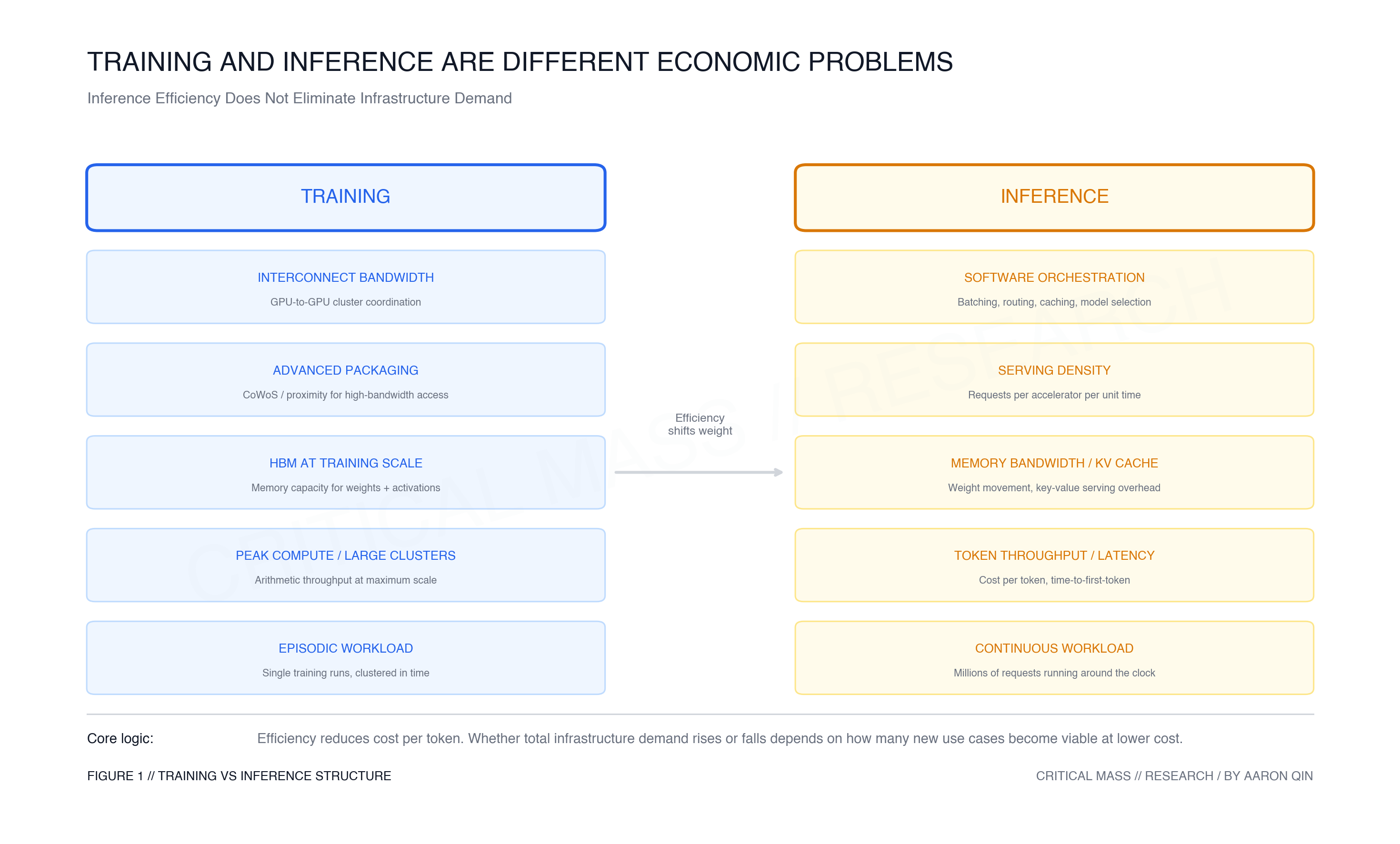
Training and inference are different economic problems, and they are often treated as if they were the same.
Training is episodic. A frontier model is trained once, or a handful of times, on a large cluster over weeks or months. The dominant constraints are peak compute, memory capacity, interconnect bandwidth, and advanced packaging. A single training run for a frontier model can consume enormous GPU-hours, concentrated in a short window. The economics are driven by cluster scale, utilization during that window, and the capital cost of assembling the hardware.
Inference is continuous. Every time a user sends a message, an agent executes a task, an enterprise workflow runs a query, or a search system retrieves and processes context, inference happens. The dominant constraints are different: token throughput, cost per token, latency, memory bandwidth for key-value cache, serving density, and utilization across a distributed fleet. The economics are driven not by peak scale but by sustained efficiency across millions or billions of requests.
These two workloads do not compete for the same infrastructure in the same way. A cluster optimized for large-batch frontier training is not the same as a fleet optimized for low-latency high-throughput inference. As AI moves from the lab into deployed products, a larger share of incremental demand may shift from the first category toward the second.
DeepSeek made that shift visible earlier than expected.
The significance of DeepSeek was not the $5.6 million figure itself, which referred to a narrow training-cost estimate and was widely debated. It was what the figure implied: that the efficiency frontier for training capable models was moving faster than many had assumed. If capable models could be trained with less compute, and served at lower cost, then the economic barrier to deploying AI at scale was lower than the frontier lab buildout suggested.
That is not automatically a demand-destruction story. It is a demand-elasticity story with a different infrastructure shape.
When the cost per token falls, more tasks become economically viable. Customer support that was too expensive to automate becomes viable. Coding assistants that required careful rationing of context become less constrained. Agents that need to call a model dozens of times per task become deployable. Enterprise workflows that were waiting for unit economics to pencil out start to move. Long-context summarization, real-time retrieval, multi-step reasoning — these all consume inference capacity, and lower unit costs make more of them worth running.
The question is not whether demand rises or falls in aggregate. The question is whether the expansion in use cases and token volume is large enough to offset the reduction in compute required per task. That is an elasticity question, and the answer depends on how fast enterprise AI adoption converts efficiency into deployment.
The infrastructure implications of this shift are not uniform across the stack.
For training-heavy suppliers, a world where capable models are trained more efficiently is a real pressure. If the compute required per frontier training run plateaus or declines, the demand for the largest clusters grows more slowly. This does not eliminate training demand — new architectures, new modalities, new scales of model will continue to require significant training infrastructure. But the case for unlimited growth in peak training clusters becomes harder to sustain on efficiency grounds alone.
For inference-oriented infrastructure, the picture is different. Sustained inference serving at scale requires sustained memory bandwidth, network throughput, power, and cooling — not episodically, but continuously. A model being queried by millions of users around the clock places different demands on infrastructure than a model being trained in a concentrated burst. More deployment means more inference infrastructure running more of the time.
Memory bandwidth is a particular constraint worth watching. Inference workloads are often memory-bound rather than compute-bound: the bottleneck is not raw arithmetic but the speed at which weights and key-value cache can be moved through the system. As model serving scales, HBM demand does not disappear — it takes a different form, distributed across serving fleets rather than concentrated in training clusters.
The software layer matters here too. Inference efficiency is not only a chip problem. Better batching, routing, caching, and model selection can raise utilization without adding equivalent hardware. In that sense, inference infrastructure is partly a hardware stack and partly an orchestration problem: the same accelerator fleet can produce very different economics depending on how requests are scheduled and served. That is why the conversion from inference demand to infrastructure revenue is not automatic — it depends on how efficiently the serving layer is built and operated.
Networking and power follow similar logic. A large inference deployment is not a smaller version of a training cluster. It is a different kind of sustained load: lower peak, longer duration, more distributed, more sensitive to latency and utilization efficiency.
The deeper implication is about where the value in AI infrastructure migrates as the workload mix shifts.
During the frontier training phase, the scarce resource was the ability to assemble and run the largest clusters. That concentrated value in compute platforms, advanced packaging, and high-bandwidth memory at training scale. As inference becomes the dominant workload by volume, the scarce resources shift: throughput per watt, cost per token, latency-optimized serving, memory bandwidth across a distributed fleet, and the software and networking infrastructure that routes and batches requests efficiently.
This does not mean training demand disappears, or that the companies that captured value in the training phase lose their positions. NVIDIA's inference business has grown alongside its training business precisely because the platform — hardware, CUDA, networking, ecosystem — spans both workloads. But it does mean that the simple story of "more frontier models equals more cluster demand equals more of everything" is incomplete.
The infrastructure layer that emerges from a world of cheaper, more widely deployed models looks different from the infrastructure layer built for concentrated frontier training. Broader deployment means more sustained load, more geographic distribution, more latency sensitivity, and more software-defined efficiency pressure. These are not smaller versions of the same problem. They are structurally different demands.
This framework would need revision under several conditions.
If inference efficiency gains prove to be one-time rather than continuous — if the efficiency curve flattens and models stop getting meaningfully cheaper to serve — then the expansion of use cases stalls with it, and the demand-reshaping story weakens. If enterprise AI adoption proves slower than expected, with pilots failing to convert into production deployments at scale, then the elasticity argument does not hold. If training demand continues to grow faster than inference workloads for longer than current trends suggest — because the next generation of frontier models requires radically larger training runs — then the training-to-inference shift is premature. And if commodity hardware and software eventually handles the bulk of inference without requiring specialized accelerators, memory bandwidth, or networking, then efficiency gains could reduce total infrastructure intensity rather than reshape it.
The claim here is not that infrastructure demand grows without limit. It is that efficiency reduces the cost of a unit of AI capability, and that lower cost tends to expand the number of units deployed. Whether that expansion is large enough to sustain or increase total infrastructure demand is an open empirical question. The January 2025 market reaction assumed it would not be. The subsequent period of hyperscaler spending suggested the opposite. Neither settled the underlying question. Both illustrated how poorly suited a single linear narrative is for a transition this complex.
This essay connects to the demand-side analysis in the AI Infrastructure Economics analytics module and the system-level framing in the Frontier Model Progress series. It does not attribute pure AI revenue at the issuer level and is not investment advice.